 會員登錄
會員登錄












機器學習(xi) 是人工智能在近期最重要的發展之一。機器學習(xi) 的理念是,不將智能看作是給機器傳(chuan) 授東(dong) 西,而是機器會(hui) 自己學習(xi) 東(dong) 西。這樣一來,機器就可以直接從(cong) 經驗(或數據)中學習(xi) 如何處理複雜的任務。
隨著計算速度和用於(yu) 編程的算法的巨大進步與(yu) 發展,機器學習(xi) 成長迅速。由此產(chan) 生的算法對我們(men) 的生活開始產(chan) 生重大影響,而且它們(men) 的表現往往勝過人類。那麽(me) ,機器學習(xi) 是如何工作的呢?
在機器學習(xi) 係統中,計算機通常是通過在相同任務的大型數據庫中進行訓練,然後自己編寫(xie) 代碼去執行一項任務。其中很大一部分涉及到識別這些任務中的模式,然後根據這些模式做出決(jue) 策。
舉(ju) 個(ge) 例子,假設一家公司正要招聘一名新員工,在招聘廣告登出之後有1000個(ge) 人申請,每個(ge) 人都投了簡曆。如果要親(qin) 自一個(ge) 個(ge) 篩選,這實在太多了,所以你想訓練一台機器來完成這項任務。
為(wei) 了做到這一點,你需要把公司過往的許多應聘者的簡曆都記錄下來。對於(yu) 每一份簡曆,你都有記錄表明這個(ge) 人是否最終被聘用了。為(wei) 了訓練機器,你拿出一半的簡曆,讓機器通過學習(xi) 這些簡曆最終是否成功地申請到了一份工作來找出其中的模式。
這樣一來,當機器收收到一份簡曆時,它就可以對這個(ge) 人是否適合被雇傭(yong) 做出判斷。訓練完畢,就可以接著用另一半簡曆來對機器進行測試。如果它的成功率足夠高,也就是機器做出正確判斷的概率夠高,那麽(me) 你就可以安心地讓機器根據一個(ge) 人的簡曆來判斷他是否適合被聘用。在任何階段都不需要人的判斷。
為(wei) 了更清楚地理解機器學習(xi) 的過程,我們(men) 將以開發能夠識別手寫(xie) 數字的機器為(wei) 具體(ti) 例子來考慮模式識別的問題。這樣的機器應該能夠準確識別一個(ge) 字符所代表的數字,而無論它的書(shu) 寫(xie) 格式如何變化。
數字識別的過程分為(wei) 兩(liang) 個(ge) 階段。首先,我們(men) 必須能夠將手寫(xie) 數字的圖像掃描到機器中,並從(cong) 這張(數字)圖像中提取出有意義(yi) 的數據。這通常是通過主成分分析(PCA)的統計方法實現的,這種方法會(hui) 自動提取圖像中的主要特征,例如圖像的長度、寬度、線條的交點等。這個(ge) 過程與(yu) 求解矩陣的本征值和本征向量的過程密切相關(guan) ,也與(yu) 穀歌用來在萬(wan) 維網上搜索信息的過程非常相似。
然後,我們(men) 想訓練機器從(cong) 這些提取的特征中識別數字。一種非常主流的用來訓練機器的方法是神經網絡。神經網絡算法的最初靈感來源是我們(men) 認為(wei) 的人類大腦的工作方式,但並不嚴(yan) 格地建立在我們(men) 認為(wei) 的人類大腦的工作方式之上。
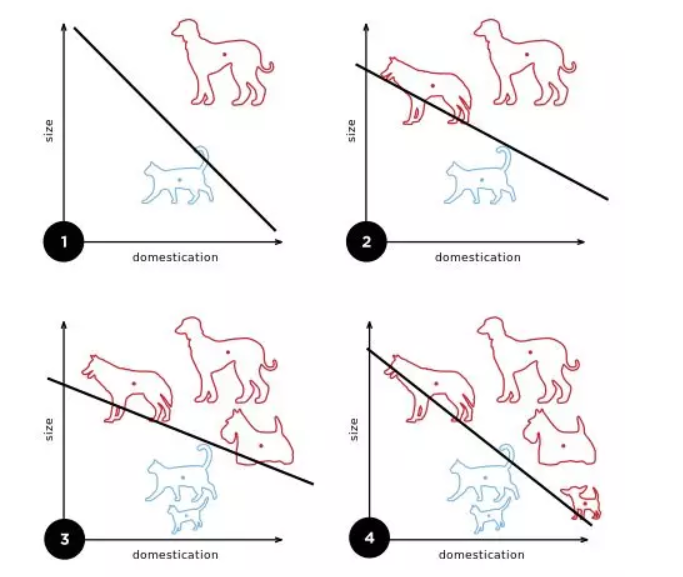
隨著訓練數據的增加,算法會(hui) 更新其選擇的直線。(圖片來源:University of Bath)
首先要創建一組“神經元”,並將它們(men) 連接起來,它們(men) 可以相互發送消息。接下來,讓神經網絡去解決(jue) 大量已經知道結果的問題,這樣做能讓算法“學習(xi) ”到應該如何確定神經元之間的連接,以便能成功地識別出數據中的哪些模式導致了正確的結果。
將許多感知機耦合在一起就可以進行更多的計算,但這一發展必須等待更強大的計算機的出現。當多層感知機耦合起來形成一個(ge) 神經網絡時,這一重大突破就出現了。這種神經網絡的典型結構如下圖所示,它包括輸入層、隱藏層和輸出層。在這種情況下,輸入會(hui) 組合起來以觸發感知機的第一層神經元,由此產(chan) 生的輸出也會(hui) 組合起來以觸發下一層神經元,最後,這些組合起來給出最終的輸出。
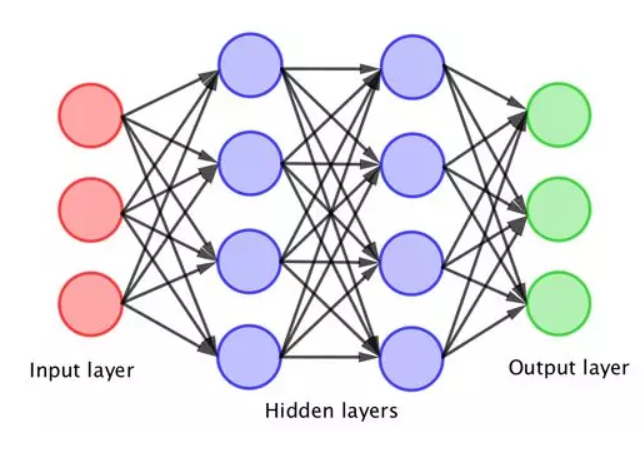
層數越多,神經網絡就越“深”。(圖片來源:University of Bath)
然後,這樣一個(ge) 神經網絡就會(hui) 通過為(wei) 上麵的神經元之間的每個(ge) 連接分配加權而得到訓練。這個(ge) 過程是為(wei) 了模仿大腦神經通路強化或衰減的方式。深度學習(xi) 描述了訓練這樣一個(ge) 神經網絡的過程。
神經網絡學習(xi) 的過程有多種形式。在監督學習(xi) 中,用戶會(hui) 事先提供一組成對的實例,也就是輸入和輸出。然後,學習(xi) 的目標是找到一個(ge) 給出的輸出能與(yu) 實例匹配的神經網絡。通常,用來比較神經網絡的輸出與(yu) 實例的輸出的方法是計算兩(liang) 者的均方誤差;然後對網絡進行訓練,讓這一誤差對所有訓練數據集最小化。這種方法的一個(ge) 非常標準的應用是在統計學中使用的曲線擬合,它對手寫(xie) 數字和其他的模式識別問題都有很好的效果。
在強化學習(xi) 中,數據不會(hui) 由用戶事先給出,而是由神經網絡控製的機器與(yu) 環境交互作用時生成的。機器會(hui) 在每個(ge) 時間點上對環境執行一個(ge) 操作,由此生成一個(ge) 觀察結果,以及這個(ge) 操作的成本。然後訓練這個(ge) 神經網絡去選擇那些將總體(ti) 成本降至最低的操作。在許多方麵,這個(ge) 過程類似於(yu) 人類學習(xi) 的方式。
機器學習(xi) 進展迅速,在更快的訓練算法和越來越多的數據的驅動下,發展更複雜、更深層神經網絡的趨勢越來越明顯。
關(guan) 注【深圳科普】微信公眾(zhong) 號,在對話框:
回複【最新活動】,了解近期科普活動
回複【科普行】,了解最新深圳科普行活動
回複【研學營】,了解最新科普研學營
回複【科普課堂】,了解最新科普課堂
回複【科普書(shu) 籍】,了解最新科普書(shu) 籍
回複【團體(ti) 定製】,了解最新團體(ti) 定製活動
回複【科普基地】,了解深圳科普基地詳情
回複【觀鳥星空体育官网入口网站】,學習(xi) 觀鳥相關(guan) 科普星空体育官网入口网站










- 參加最新科普活動
- 認識科普小朋友
- 成為科學小記者




