 會員登錄
會員登錄











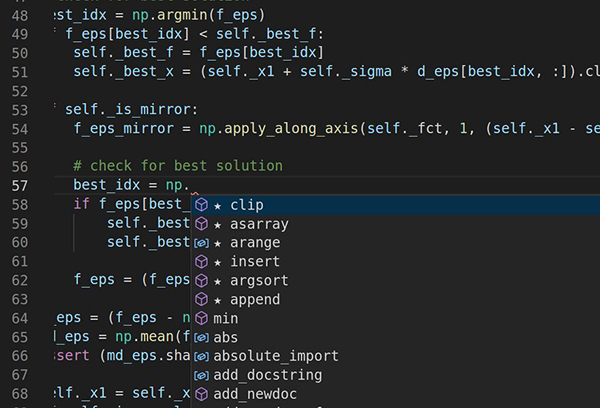
MIT(麻省理工學院)和IBM(國際商業(ye) 機器公司)研究人員搭建的框架能找到並修複使自動編程工具容易受到攻擊的薄弱點。其中一個(ge) 工具(圖示)在程序員寫(xie) 代碼的同時瀏覽並提出建議。本圖中,該工具從(cong) Python的NumPy庫的數千個(ge) 選項中選出最適合當前情況的函數。(圖片來源:Shashank Srikant)
無論一個(ge) 公司的業(ye) 務領域是什麽(me) ,軟件在從(cong) 管理庫存到與(yu) 客戶溝通中,都扮演著越來越關(guan) 鍵的角色。因此,軟件開發員的需求比以往任何時候都要大,這推動了一些花費時間的簡單任務的自動化。
如Eclipse和Visual Studio一類的生產(chan) 力工具會(hui) 提供一小段代碼,這些代碼使開發人員在編程時可以輕鬆地投入到他們(men) 的工作中。這些自動功能由複雜的語言模型提供支持,這些語言模型在吸收了成千上萬(wan) 的示例後學會(hui) 了讀寫(xie) 計算機代碼。但是就像其他在沒有指令的情況下在大型數據集上進行訓練的深度學習(xi) 模型一樣,為(wei) 代碼處理而設計的語言模型也存在固有漏洞。
“除非你非常小心,否則黑客可以通過巧妙地操縱這些模型的輸入讓它們(men) 預測任何東(dong) 西。”麻省理工學院電氣工程和計算機科學係的研究生Shashank Srikant說,“我們(men) 正努力研究和防止這樣的事發生。”
在一篇新論文中,Srikant和MIT-IBM Watson AI實驗室推出了一種自動方法,可以發現代碼處理模型中的弱點,然後重新訓練它們(men) 以使其更能抵禦攻擊。這是麻省理工學院的研究員Una-May O'Reilly和IBM的研究員Sijia Liu所做的更廣泛努力的一部分,以利用AI來使自動化編程工具更智能、更安全。該團隊將在下月的國際學習(xi) 表征會(hui) 議(International Conference on Learning Representations)上展示其成果。
人工智能、機器學習(xi) 、深度學習(xi) (圖片來源:Wikipedia)
能夠為(wei) 自己編程的機器曾經讓人感覺像是科幻小說。但是計算機能力指數式的增長、自然語言處理的進步,還有互聯網上大量免費代碼的出現讓自動化成為(wei) 可能,至少是在軟件設計方麵。
在GitHub和其他程序共享網站上,代碼處理模型可以學習(xi) 生成程序,就像其他語言模型可以學習(xi) 寫(xie) 新故事或者詩歌一樣。這讓它們(men) 可以充當智能助手,預測軟件開發員接下來會(hui) 做什麽(me) ,然後提供幫助。它們(men) 可能會(hui) 提供適合當前任務的程序,或者生成程序摘要,以描述程序如何運作。代碼處理模型還能通過訓練尋找和修複錯誤。但是,盡管有提高生產(chan) 力和軟件質量的潛力,它們(men) 還可能產(chan) 生研究人員正剛剛開始研究的安全風險。
Srikant和他的同事發現,僅(jin) 僅(jin) 通過重命名變量、插入偽(wei) 造的打印輸出語句,或者是將其他修飾操作加入模型要處理的程序中,就可能輕易欺騙代碼處理模型。這些經過細微處理的程序能正常運行,但是會(hui) 導致模型處理方式錯誤,返回錯誤的決(jue) 定。
這種錯誤會(hui) 對各種代碼處理軟件造成嚴(yan) 重的影響。一個(ge) 惡意程序監測模型可能會(hui) 被欺騙,把一個(ge) 惡意程序判斷為(wei) 良性。一個(ge) 代碼處理模型可能會(hui) 被欺騙以致提供錯誤的或者是惡意的建議。在這兩(liang) 種情況下,病毒都可能逃過毫無戒心的程序員。一個(ge) 類似的問題困擾著計算機視覺模型:麻省理工學院的其他研究表明,修改輸入圖片的幾個(ge) 關(guan) 鍵的像素,就可能讓模型把豬當成飛機,把烏(wu) 龜當成步槍。
就像那些最棒的語言模型一樣,代碼處理模型也有一個(ge) 關(guan) 鍵的缺陷。它們(men) 是單詞和句子之間統計關(guan) 係方麵的專(zhuan) 家,但是僅(jin) 僅(jin) 大致了解它們(men) 的真實含義(yi) 。舉(ju) 例來說,OpenAI的GPT-3模型寫(xie) 出的詩句既有意味深長的,也有荒謬不堪的,但是隻有人類才能區分這一點。
深度學習(xi) ——圖片識別 (圖片來源:Wikipedia)
代碼處理模型與(yu) 此並無區別。“如果它們(men) 真的能學習(xi) 程序中的內(nei) 在含義(yi) ,那欺騙它們(men) 會(hui) 十分困難,”Srikant說,“但是實際上並不是這樣。目前它們(men) 很容易被欺騙。”
在本文中,研究人員提出一個(ge) 框架,該框架能自動改變程序,以發現處理程序的模型中薄弱的環節。它解決(jue) 了包含兩(liang) 個(ge) 部分的優(you) 化問題:框架中的算法能分辨程序哪部分加入或替換文本會(hui) 導致最大的錯誤,還能分辨哪種編輯對程序造成最大威脅。
研究人員表示,這個(ge) 框架僅(jin) 揭示了一些模型的脆弱性。在對程序做出一個(ge) 簡單的編輯後,他們(men) 的文本摘要模型失敗率達三分之一。他們(men) 還報告說,當程序做出五處編輯後,模型失敗次數超過一半。另一方麵,他們(men) 說明了模型有能力從(cong) 錯誤中學習(xi) ,並在學習(xi) 過程中獲得對程序更深的理解。
“我們(men) 用於(yu) 攻擊模型並針對那些特定漏洞進行再訓練的框架可能會(hui) 幫助代碼處理模型更好地了解程序的意圖。”該研究的共同資深作者Liu說,“這是一個(ge) 有待探索、令人興(xing) 奮的方向。”
在深度學習(xi) 的大背景下,仍然存在著一個(ge) 更大的問題:這些深度學習(xi) 模型黑盒到底在學習(xi) 什麽(me) ?“它們(men) 會(hui) 像人類一樣分析代碼嗎?如果不是這樣,我們(men) 怎樣讓它們(men) 做到?”O'Reilly說,“這是我們(men) 麵臨(lin) 的巨大挑戰。”
作者:Kim Martineau
翻譯:王嘉鈺
審校:汪茹
引進來源:麻省理工學院
關(guan) 注【深圳科普】微信公眾(zhong) 號,在對話框:
回複【最新活動】,了解近期科普活動
回複【科普行】,了解最新深圳科普行活動
回複【研學營】,了解最新科普研學營
回複【科普課堂】,了解最新科普課堂
回複【科普書(shu) 籍】,了解最新科普書(shu) 籍
回複【團體(ti) 定製】,了解最新團體(ti) 定製活動
回複【科普基地】,了解深圳科普基地詳情
回複【觀鳥星空体育官网入口网站】,學習(xi) 觀鳥相關(guan) 科普星空体育官网入口网站
回複【博物學院】,了解更多博物學院活動詳情















- 參加最新科普活動
- 認識科普小朋友
- 成為科學小記者




