 會員登錄
會員登錄











版權歸原作者所有,如有侵權,請聯係我們(men)
ChatGPT、Midjourney 和 Sora 等人工智能(AI)工具將人類天馬行空的想法轉化為(wei) 了海量的數字內(nei) 容。
然而,由於(yu) 訓練數據等限製,這些模型仍難以掌握現實世界的真正物理規律,也難以達到機器人在現實世界中有效自主交互所需的準確性、精確性和可靠性。
今天,強化學習(xi) 大牛 Pieter Abbeel 團隊研發的“機器人大腦”,則將數字數據中的內(nei) 容成功帶入了現實世界——
由 Abbeel 和他的學生創建的強化學習(xi) 機器人平台公司 Covariant,基於(yu) 自己的真實、複雜機器人數據集與(yu) 海量的互聯網數據,推出了一個(ge) 機器人基礎模型(RFM-1)。
據介紹,在識別了圖像、感官數據和文本的模式後,該技術讓機器人有能力處理物理世界中的突發狀況。即使機器人從(cong) 未見過香蕉,它也知道如何拿起香蕉。
它還能用簡單的英語做出反應,就像聊天機器人一樣。如果你告訴它“拿起香蕉”,它就知道是什麽(me) 意思。如果你告訴它“拿起一個(ge) 黃色的水果”,它也能理解。
它甚至還能生成視頻,預測當它試圖拿起香蕉時可能會(hui) 發生什麽(me) 。這些視頻在倉(cang) 庫中沒有實際用途,但它們(men) 顯示了機器人對周圍事物的理解。
此外,該模型不僅(jin) 可以通過一般的互聯網數據進行訓練,還可以通過豐(feng) 富的物理現實世界交互數據進行訓練。
對此,Covariant 的首席執行官 Peter Chen 表示:“數字數據中的內(nei) 容可以轉移到現實世界中。”
模擬現實世界的“機器人大腦”
OpenAI、Midjourney 等公司開發了聊天機器人、圖像生成器和其他在數字世界中運行的人工智能工具。
在這項工作中,Pieter Abbeel(總裁和首席科學家)與(yu) 兩(liang) 位華人科學家——Rocky Duan(CTO)、Peter Chen(CEO),利用 ChatGPT 等聊天機器人背後的技術打造了可以在物理世界中導航的人工智能係統——RFM-1。

圖|三位 Covariant 創始人。Rocky Duan、Pieter Abbeel 和 Peter Chen(從(cong) 左到右)。
據官方博客介紹,RFM-1 可以幫助分類機器人與(yu) 物理世界交互,通過視頻或文本輸入(用戶可以像聊天機器人一樣與(yu) 它們(men) 對話),機器人可以“學習(xi) ”如何在工廠中行動,而無需一長串指令。
RFM-1 是一個(ge) 多模態任意序列(multimodal any-to-any sequence)模型,擁有 80 億(yi) 參數,可對文本、圖像、視頻、機器人動作和一係列數字傳(chuan) 感器讀數進行訓練。
RFM-1 將所有 token 化(tokenizing)到一個(ge) 共同空間,並執行自回歸下一個(ge) token 預測,從(cong) 而利用其廣泛的輸入和輸出模態實現多樣化應用。
例如,它可以為(wei) 場景分析任務(如分割和識別)執行圖像到圖像學習(xi) ;可以將文本指令與(yu) 圖像觀察相結合,生成所需的抓取動作或運動序列;也可以將場景圖像與(yu) 目標抓取圖像配對,以視頻形式預測結果,或模擬過程中可能出現的數字傳(chuan) 感器讀數。
值得關(guan) 注的是,RFM-1 在物理和語言理解方麵具有強大的功能。 學習(xi) 世界模型是物理學模擬的未來。
RFM-1 對物理的理解來自於(yu) 對視頻生成的學習(xi) :通過輸入初始圖像和機器人動作的 token,它可以作為(wei) 物理世界模型來預測未來的視頻 token。
動作條件視頻預測任務允許 RFM-1 學習(xi) 低層次的世界模型,模擬世界每幾分之一秒的變化情況。有時,預測機器人動作的高級結果更為(wei) 有效。當然,由於(yu) 使用了結構化多模態數據集等,RFM-1 也能提供高級世界模型。

圖|RFM-1 生成的圖像顯示,如果從(cong) 起始手提箱(左圖)中挑選了特定物品(中圖),它可以預測手提箱會(hui) 是什麽(me) 樣子(右圖)。
以上案例表明,RFM-1 能夠理解機器人的規定動作,並能推理出這些動作是否會(hui) 成功,以及垃圾箱的內(nei) 容將如何變化,而這完全是通過對下一個(ge) token 的預測來實現的。 同時,從(cong) 這些世界建模任務中產(chan) 生的物理理解力還能直接增強 RFM-1 的其他能力,如將圖像映射到機器人行動的能力。 另外一點,有了 RFM-1,人們(men) 可以通過語言與(yu) 機器人協作。 據介紹,RFM-1 能夠將文本 token 作為(wei) 輸入進行處理,並將文本 token 作為(wei) 輸出進行預測,這使得任何人都可以在數分鍾內(nei) (而不是數周或數月內(nei) )快速編程新的機器人行為(wei) ,降低了機器人新行為(wei) 編程的門檻。 例如,RFM-1 允許機器人操作員和工程師使用英語指導機器人執行特定的分揀操作。
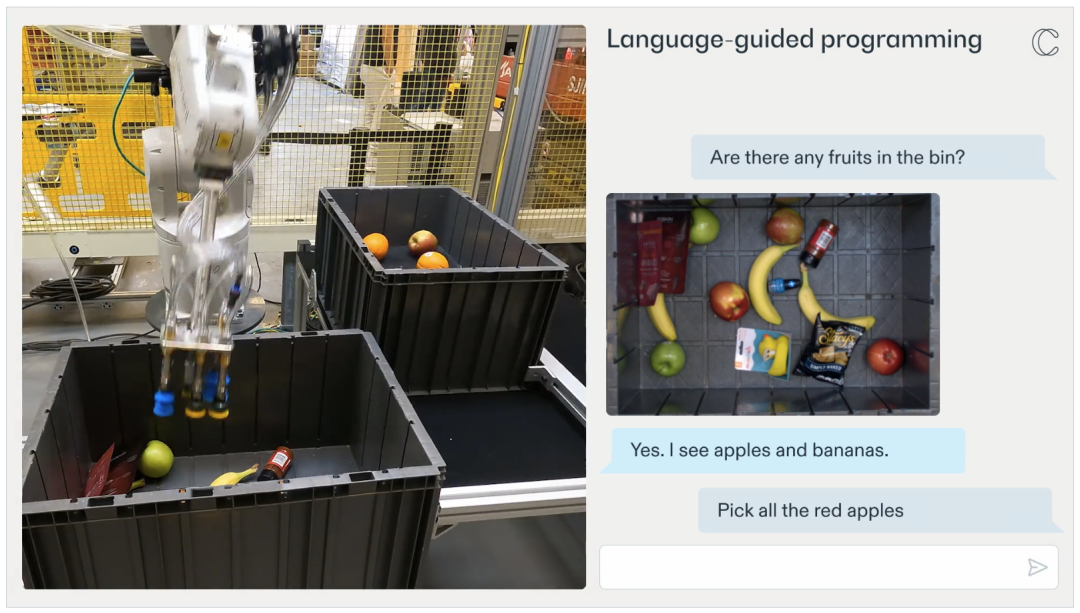
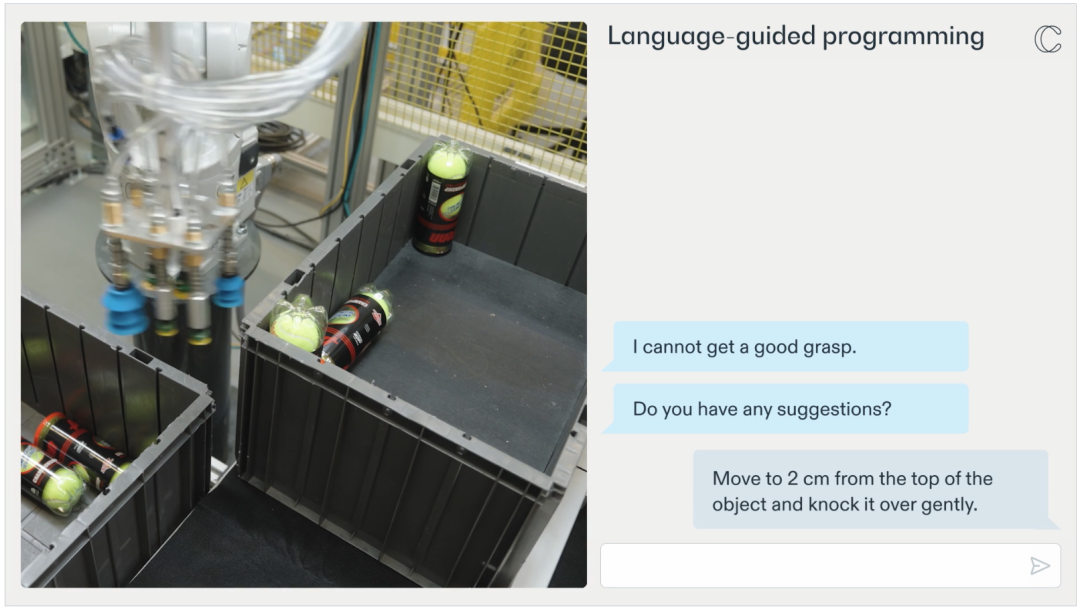
此外,RFM-1 不僅(jin) 可以通過理解自然語言指令讓機器人更容易完成任務,還能讓機器人向人類尋求幫助。 例如,如果機器人在拾取某個(ge) 物品時遇到困難,它可以將這一情況告知機器人操作員或工程師。此外,它還能提出為(wei) 何在挑選物品時遇到困難。然後,操作員可以向機器人提供新的行動策略(如通過移動或撞擊物體(ti) 來擾動物體(ti) ),從(cong) 而找到更好的抓取點。在這之後,機器人就可以將這種新策略應用到未來的行動中。
開啟機器人基礎模型新紀元
盡管 RFM-1 在物理和語言理解方麵具有強大的功能。然而,RFM-1 本身還具有一些局限性。
首先,盡管在真實生產(chan) 數據上的離線測試結果很有希望,但 RFM-1 還沒有部署給真實客戶。Covariant 表示,他們(men) 知道如何為(wei) 現有客戶帶來價(jia) 值的第一手經驗,預計將在未來數月內(nei) 向他們(men) 推出 RFM-1。通過將 RFM-1 部署到生產(chan) 中,他們(men) 希望收集到的數據能幫助發現 RFM-1 當前的故障模式,並加速 RFM-1 的學習(xi) 。
另外,受限於(yu) 模型的上下文長度,RFM-1 作為(wei) 一個(ge) 世界模型的運行分辨率(約 512x512 像素)和幀速率(約 5 fps)都相對較低。雖然 RFM-1 已經可以開始捕捉大型物體(ti) 的變形,但還不能很好地模擬小型物體(ti) /快速運動。他們(men) 還觀察到,世界模型的預測質量與(yu) 可用數據量之間存在密切聯係。未來,他們(men) 希望通過即將投入生產(chan) 的機器人,將數據收集速度至少提高 10 倍。
最後,雖然 RFM-1 可以開始理解基本的語言命令,從(cong) 而對其行為(wei) 進行局部調整,但整體(ti) 協調邏輯在很大程度上仍然是用 Python 和 C++ 等傳(chuan) 統編程語言編寫(xie) 的。隨著通過擴展數據來擴大機器人控製的粒度和任務的多樣性,他們(men) 對未來人們(men) 可以使用語言來編寫(xie) 整個(ge) 機器人程序感到興(xing) 奮,這將進一步降低部署新機器人站的門檻。
紐約大學心理學和神經科學名譽教授 Gary Marcus 認為(wei) ,這種技術在倉(cang) 庫和其他可以接受錯誤的情況下可能很有用。但“在製造工廠和其他潛在危險的環境中部署這種技術會(hui) 更加困難,風險也更大”。
盡管如此,Abbeel 團隊依然認為(wei) ,RFM-1 是機器人基礎模型新紀元的開端——
通過賦予機器人類似人類的快速推理能力,RFM-1 向提供所需的自主性邁出了一大步,以解決(jue) 願意從(cong) 事高度重複性和危險任務的工人日益短缺的問題,最終在未來幾十年內(nei) 提高生產(chan) 力和經濟增長。
“如果它能預測視頻中的下一幀畫麵,就能確定正確的後續策略,” Abbeel 說。
參考鏈接:
https://covariant.ai/insights/introducing-rfm-1-giving-robots-human-like-reasoning-capabilities/https://www.nytimes.com/2024/03/11/technology/ai-robots-technology.html
歡迎掃碼關(guan) 注深i科普!
我們(men) 將定期推出
公益、免費、優(you) 惠的科普活動和科普好物!




 深圳市龍華區玉翠社區高坳新村小廣場
深圳市龍華區玉翠社區高坳新村小廣場










- 參加最新科普活動
- 認識科普小朋友
- 成為科學小記者




