 會員登錄
會員登錄











現在企業(ye) 越來越重視運用人工智能技術洞察數據價(jia) 值,從(cong) 中發展增值業(ye) 務。傳(chuan) 統的依賴業(ye) 務規則篩選目標用戶的營銷方式,存在獲取數據周期長且營銷接觸率低的問題。本文將介紹當下流行的相似人群擴展(Lookalike)技術,能有效支撐業(ye) 務方進行精準營銷。
1、Lookalike技術是什麽(me)
Lookalike技術,即相似人群擴展技術,是一種從(cong) 小規模的目標用戶群體(ti) 中,通過算法模型找到更大規模相似用戶群體(ti) 的方法。其核心思路是首先根據一小部分目標用戶(種子用戶)的特征,比如人口統計學數據、網絡行為(wei) 、消費偏好等,建立這部分目標用戶的畫像。然後,在更大範圍的用戶總體(ti) 中,找到與(yu) 這些目標用戶較為(wei) 相似的用戶。這些新找到的用戶就是目標用戶的“相似”群體(ti) 。
圖1 什麽(me) 是Lookalike
需要注意的是,lookalike技術並不是某一類特定的算法,而是一係列算法方法的統稱。這些算法綜合運用機器學習(xi) 、統計分析、數據挖掘等多種技術手段,通過對用戶特征的評估和建模,達到從(cong) 小規模目標用戶擴展到更大相似用戶群的目的。
2、Lookalike技術怎麽(me) 用
Lookalike技術核心價(jia) 值在於(yu) 實現小規模用戶的精準擴充。具體(ti) 來說,在實際業(ye) 務中,廣告主會(hui) 基於(yu) 自己的規則和經驗先選取出一小部分高質量的典型用戶作為(wei) 種子用戶。這些種子用戶能夠精準代表目標客戶群體(ti) ,但由於(yu) 選取規則設置嚴(yan) 格,導致精準的目標客戶數量有限。此時,通過Lookalike算法分析種子用戶的特征屬性,再從(cong) 全量用戶庫中找出與(yu) 之相似的用戶。新匹配的這些用戶,因為(wei) 與(yu) 原種子用戶在某些維度比較相似,所以能滿足業(ye) 務的營銷需求。如此,Lookalike算法就能根據有限的種子用戶,對用戶群進行效果顯著的擴展,以不斷滿足廣告主獲取更多優(you) 質客戶的需求。
舉(ju) 個(ge) 汽車銷售的例子,某汽車品牌要在一個(ge) 新興(xing) 城市推廣它的新款SUV,目標是覆蓋該城市100萬(wan) 有購車意向的駕駛者。但根據這一車型的曆史購買(mai) 數據,目標購車人群隻有20萬(wan) 。為(wei) 了觸達更多潛在客戶,該汽車品牌采用了Lookalike技術,先選擇近期詢價(jia) 或參觀過這一車型的客戶作為(wei) 種子用戶,然後根據這些種子用戶的特征,如地區、收入、生活方式等,在該城市全體(ti) 駕駛人群中匹配出80萬(wan) 與(yu) 之類似的用戶。這樣一來,這次推廣就可以觸達更多符合品牌價(jia) 值觀和購車偏好的目標人群。
再舉(ju) 個(ge) 教育培訓的例子,某在線教育平台準備推出一個(ge) Python編程課程,目標是向5000名學生推送該課程信息。但根據平台的注冊(ce) 用戶數據,可能隻有1000名對Python感興(xing) 趣。為(wei) 了擴大課程的影響力,平台決(jue) 定運用Lookalike技術,先選擇最近1年內(nei) 報名學習(xi) 過編程課程的注冊(ce) 用戶作為(wei) 種子群體(ti) ,他們(men) 代表了有需求的用戶屬性。然後,平台可以根據這部分種子用戶的特征,例如學曆背景、職業(ye) 方向、學習(xi) 偏好等,從(cong) 全部注冊(ce) 用戶中匹配出4000名與(yu) 種子用戶類似的潛在感興(xing) 趣用戶。這樣,新課程就可以觸達到更多對編程有需求的目標學生。
3、Lookalike技術怎麽(me) 實現
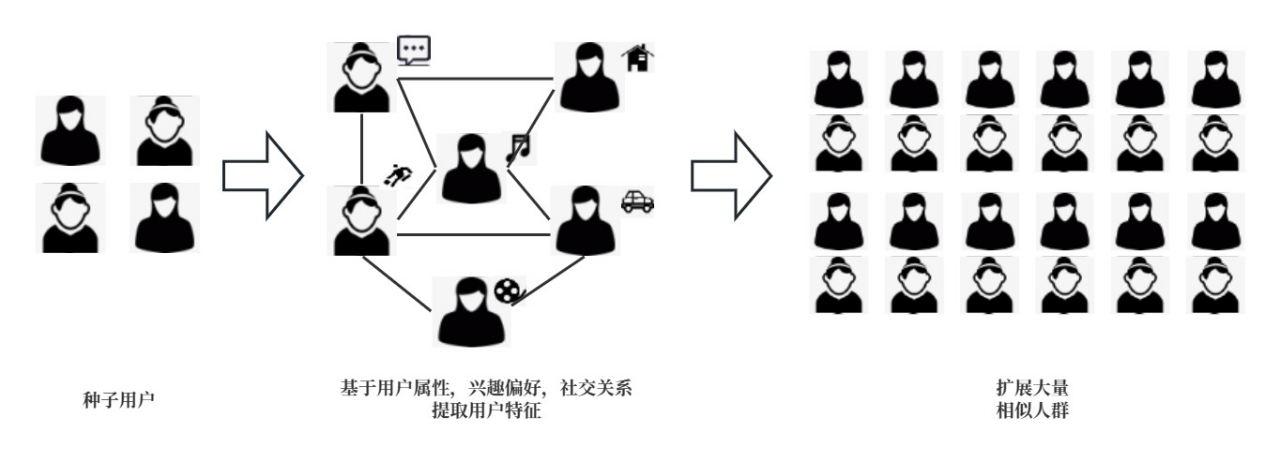
圖2 如何實現Lookalike
Lookalike相似人群拓展方法主要有以下幾種方法:
(1)基於(yu) 用戶屬性的顯式Lookalike
此類方法依據用戶的屬性特征來發現相似用戶,具體(ti) 可以使用人口統計學特征如年齡、收入、教育程度、地區等。使用時,可以先定義(yi) 好要匹配的核心屬性,然後在用戶群中提取具有相近屬性值的用戶。這種方法實現簡單,但僅(jin) 限於(yu) 預先定義(yi) 的幾個(ge) 屬性,可能會(hui) 遺漏描述用戶的其他隱性特征。
(2)基於(yu) 用戶行為(wei) 的隱式Lookalike
此類方法會(hui) 全麵分析各類用戶行為(wei) 數據,例如頁麵瀏覽時間、點擊頻率、搜索詞、消費金額、興(xing) 趣等,將種子用戶作為(wei) 正樣本,將隨機用戶進行降采樣後作為(wei) 負樣本,運用機器學習(xi) 算法建模用戶的興(xing) 趣和消費偏好,然後匹配具有類似偏好和行為(wei) 的用戶。優(you) 點是可以充分利用豐(feng) 富的用戶行為(wei) 數據,缺點是需要收集大量行為(wei) 數據進行建模。
(3)基於(yu) 圖數據庫進行隱式Lookalike
此類方法在圖數據庫中構建用戶節點和用戶關(guan) 係邊的網絡結構,識別種子用戶後,依托節點之間的邊關(guan) 係進行特征與(yu) 標簽向相鄰節點的傳(chuan) 播擴散,通過遞歸迭代不斷在網絡圖中發現新的相似用戶,重複該過程直到發現足夠數量的人群,從(cong) 而實現對目標用戶的高效擴充。這種技術充分利用圖數據庫對網絡數據的建模與(yu) 計算優(you) 勢,能有效發掘更多不易觀察的相似用戶,但需要處理大規模關(guan) 係圖的存儲(chu) 和計算問題。
本文介紹了Lookalike技術的相關(guan) 概念和應用方法,但在實際業(ye) 務應用中,如何科學選擇特征來描述用戶,以保證後續算法的效果,以及如何收集營銷反饋來持續優(you) 化機器學習(xi) 模型,形成閉環,都是需要解決(jue) 的關(guan) 鍵問題。總之,任何算法並不是孤立存在的,必須結合數據及業(ye) 務場景進行合理的應用才能發揮最大的價(jia) 值。
參考資料
【1】煉丹筆記.搜推廣遇上用戶畫像:Lookalike相似人群拓展算法| CSDN, 2021
作者:張豪
單位:中國移動智慧家庭運營中心
歡迎掃碼關(guan) 注深i科普!
我們(men) 將定期推出
公益、免費、優(you) 惠的科普活動和科普好物!
















- 參加最新科普活動
- 認識科普小朋友
- 成為科學小記者




